Research idea generation methods have evolved through techniques like iterative novelty boosting, multi-agent collaboration, and multi-module retrieval. These approaches aim to enhance idea quality and novelty in research contexts. Previous studies primarily focused on improving generation methods over basic prompting, without comparing results against human expert baselines. Large language models (LLMs) have been applied to various research tasks, including experiment execution, automatic review generation, and related work curation. However, these applications differ from the creative and open-ended task of research ideation addressed in this paper.
The field of computational creativity examines AI’s ability to produce novel and diverse outputs. Previous studies indicated that AI-generated writings tend to be less creative than those from professional writers. In contrast, this paper finds that LLM-generated ideas can be more novel than those from human experts in research ideation. Human evaluations have been conducted to assess the impact of AI exposure or human-AI collaboration on novelty and diversity, yielding mixed results. This study includes a human evaluation of idea novelty, focusing on comparing human experts and LLMs in the challenging task of research ideation.

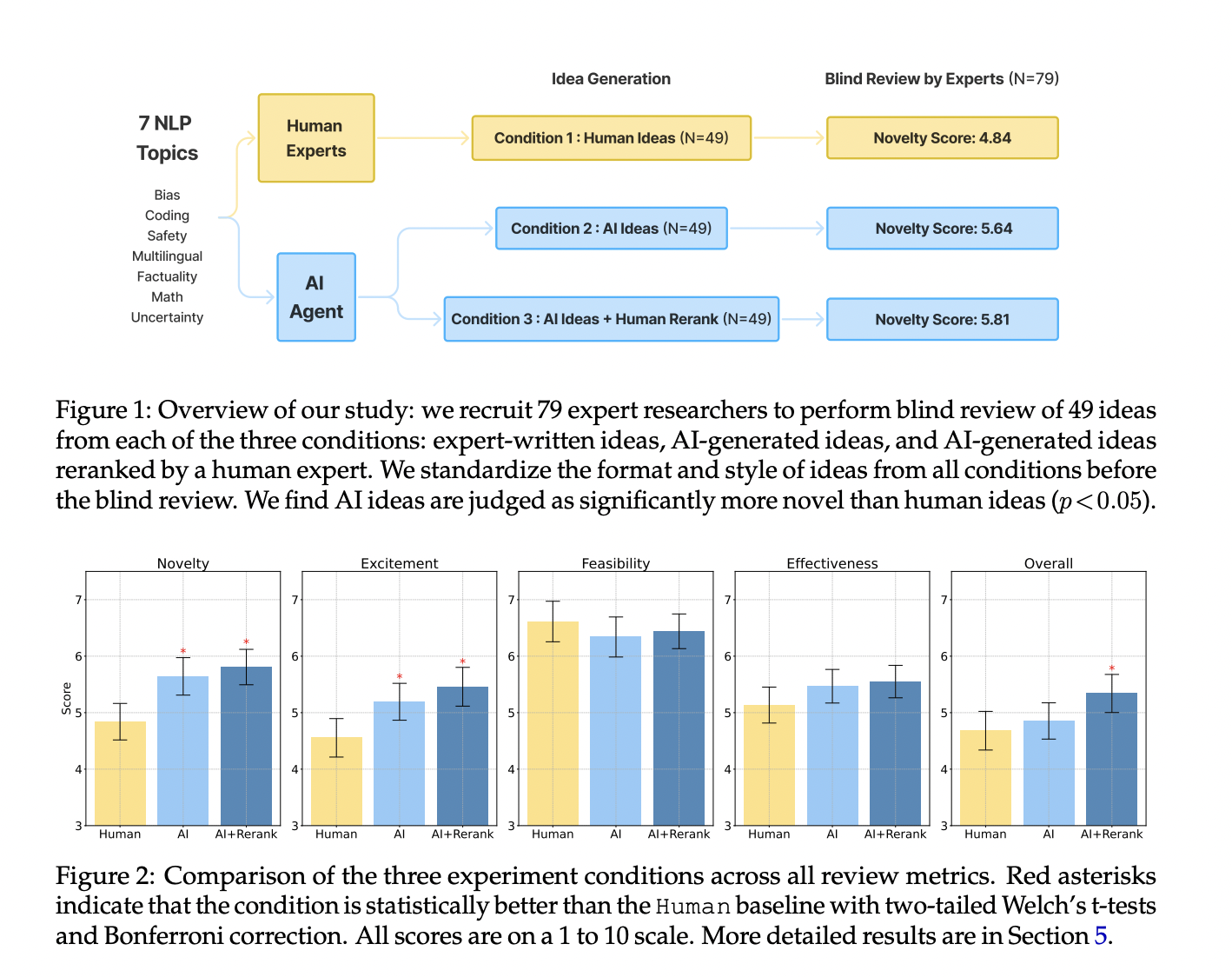
Recent advancements in LLMs have sparked interest in developing research agents for autonomous idea generation. This study addresses the lack of comprehensive evaluations by rigorously assessing LLM capabilities in producing novel, expert-level research ideas. The experimental design compares an LLM ideation agent with expert NLP researchers, recruiting over 100 participants for idea generation and blind reviews. Findings reveal LLM-generated ideas as more novel but slightly less feasible than human-generated ones. The study identifies open problems in building and evaluating research agents, acknowledges challenges in human judgments of novelty, and proposes a comprehensive design for future research involving idea execution into full projects.
Researchers from Stanford University have introduced Quantum Superposition Prompting (QSP), a novel framework designed to explore and quantify uncertainty in language model outputs. QSP generates a ‘superposition’ of possible interpretations for a given query, assigning complex amplitudes to each interpretation. The method uses ‘measurement’ prompts to collapse this superposition along different bases, yielding probability distributions over outcomes. QSP’s effectiveness will be evaluated on tasks involving multiple valid perspectives or ambiguous interpretations, including ethical dilemmas, creative writing prompts, and open-ended analytical questions.
The study also presents Fractal Uncertainty Decomposition (FUD), a technique that recursively breaks down queries into hierarchical structures of sub-queries, assessing uncertainty at each level. FUD decomposes initial queries, estimates confidence for each sub-component, and recursively applies the process to low-confidence elements. The resulting tree of nested confidence estimates is aggregated using statistical methods and prompted meta-analysis. Evaluation metrics for these methods include diversity and coherence of generated superpositions, ability to capture human-judged ambiguities, and improvements in uncertainty calibration compared to classical methods.
The study reveals that LLMs can generate research ideas judged as more novel than those from human experts, with statistical significance (p < 0.05). However, LLM-generated ideas were rated slightly lower in feasibility. Over 100 NLP researchers participated in generating and blindly reviewing ideas from both sources. The evaluation used metrics including novelty, feasibility, and overall effectiveness. Open problems identified include LLM self-evaluation issues and lack of idea diversity. The research proposes an end-to-end study design for future work, involving the execution of generated ideas into full projects to assess the impact of novelty and feasibility judgments on research outcomes.
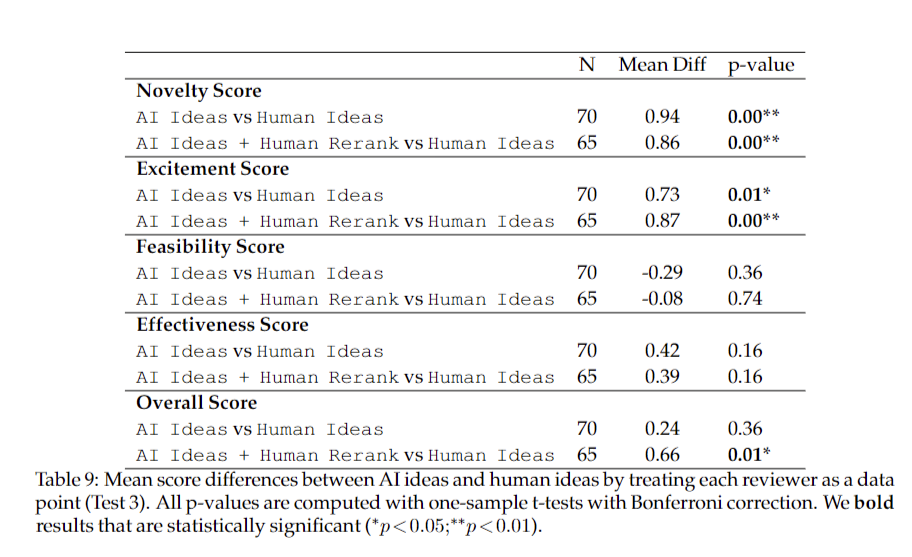
In conclusion, this study provides the first rigorous comparison between LLMs and expert NLP researchers in generating research ideas. LLM-generated ideas were judged more novel but slightly less feasible than human-generated ones. The research identifies open problems in LLM self-evaluation and idea diversity, highlighting challenges in developing effective research agents. Acknowledging the complexities of human judgments on novelty, the authors propose an end-to-end study design for future research. This approach involves executing generated ideas into full projects to investigate how differences in novelty and feasibility judgments translate into meaningful research outcomes, addressing the gap between idea generation and practical application.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
⏩ ⏩ FREE AI WEBINAR: ‘SAM 2 for Video: How to Fine-tune On Your Data’ (Wed, Sep 25, 4:00 AM – 4:45 AM EST)

Shoaib Nazir is a consulting intern at MarktechPost and has completed his M.Tech dual degree from the Indian Institute of Technology (IIT), Kharagpur. With a strong passion for Data Science, he is particularly interested in the diverse applications of artificial intelligence across various domains. Shoaib is driven by a desire to explore the latest technological advancements and their practical implications in everyday life. His enthusiasm for innovation and real-world problem-solving fuels his continuous learning and contribution to the field of AI