


Introduction
Training computer vision models requires precise learning rate adjustments to balance speed and accuracy. Cyclical Learning Rate (CLR) schedules offer a dynamic approach, alternating between minimum and maximum values to help models learn more effectively, avoid local minima, and generalize better. This method is particularly powerful for complex tasks like image classification and segmentation. In this post, we’ll explore how CLR works, popular patterns, and practical tips to enhance model training.
Defining Learning rate
The learning rate is a fundamental concept in machine learning and deep learning that controls how much a model’s weights are adjusted in response to the error it experiences during each step of training. Think of it as a step size that determines how quickly or slowly a model “learns” from data.
Key Points About Learning Rate
- Role in Training:
- During training, a model makes predictions and calculates the error between its predictions and the actual results. The learning rate determines the size of the steps the model takes to adjust its weights to minimize this error. This adjustment is usually done through an optimization algorithm like gradient descent.
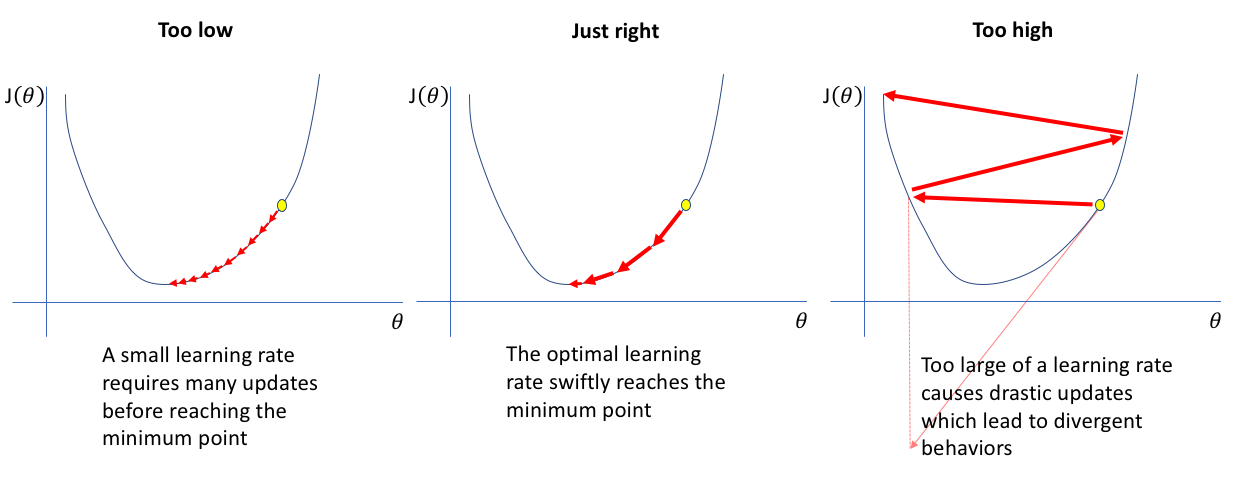
2.Setting the Right Pace:
- Too High: A high learning rate might lead to very large steps, causing the model to “overshoot” the optimal values for weights. This can make training unstable and prevent the model from converging, leading to high error.
- Too Low: A low learning rate means very small steps. The model will adjust weights slowly, which can make training take longer and even risk getting stuck in local minima—suboptimal points in the error landscape.
3.Finding a Balance:
- The ideal learning rate allows the model to make meaningful adjustments without overshooting the optimal point. Setting this rate well can help the model converge faster while also ensuring that it reaches the best possible performance.
4.Dynamic Learning Rate Adjustments:
To improve performance, various techniques dynamically adjust the learning rate during training. For example:
- Learning Rate Decay: Gradually lowers the learning rate over time.
- Cyclical Learning Rate (CLR): Alternates the learning rate within a specified range to allow more dynamic learning, which can be especially helpful in complex tasks like computer vision.

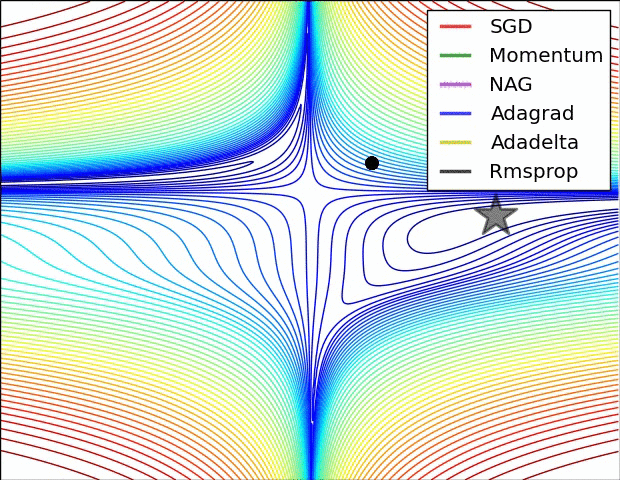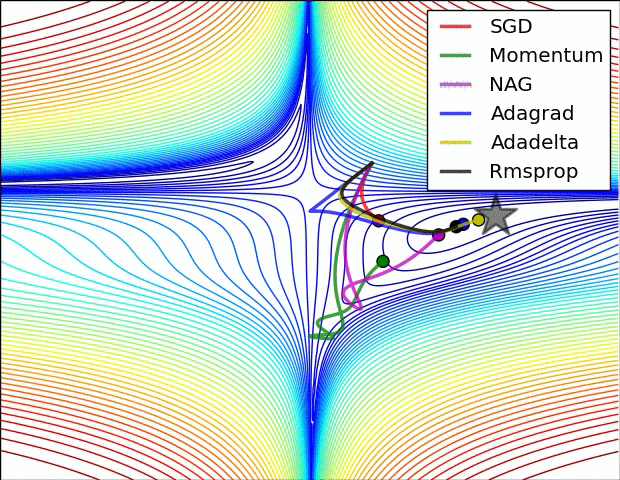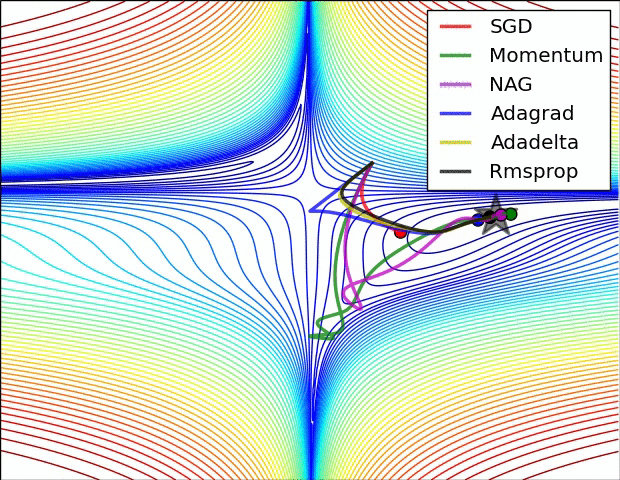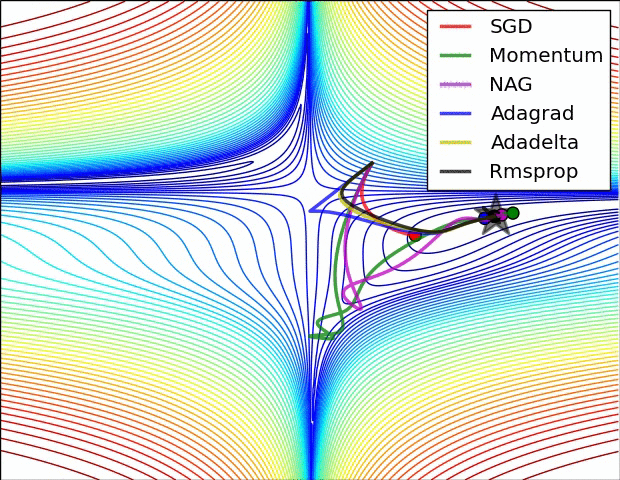

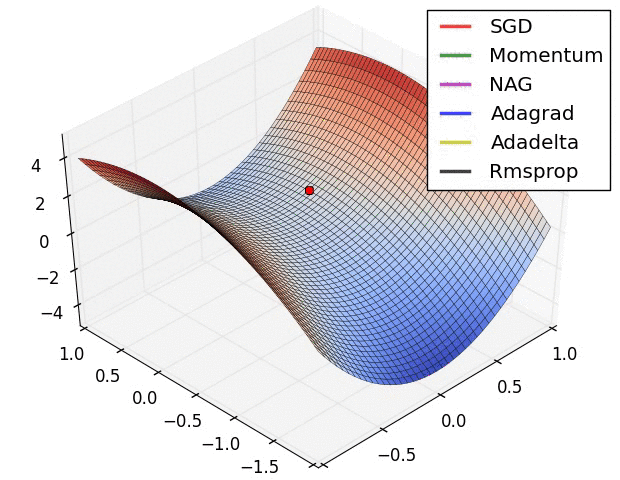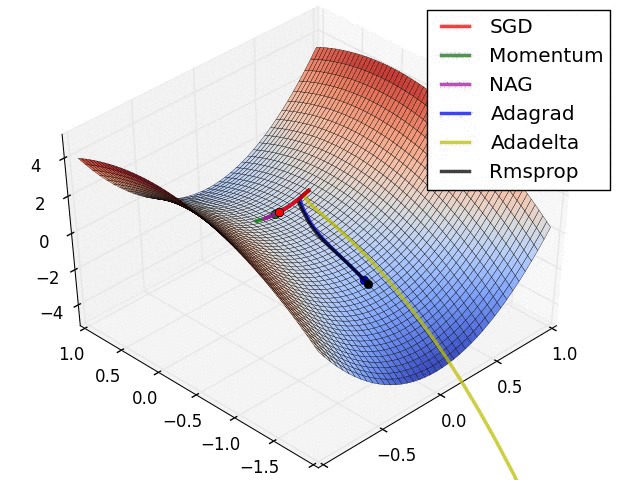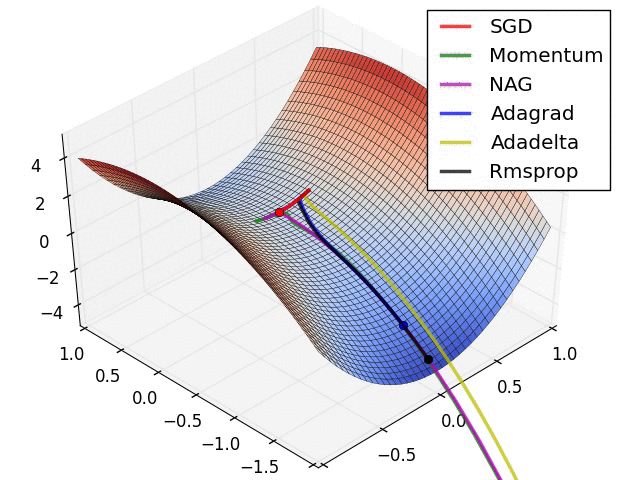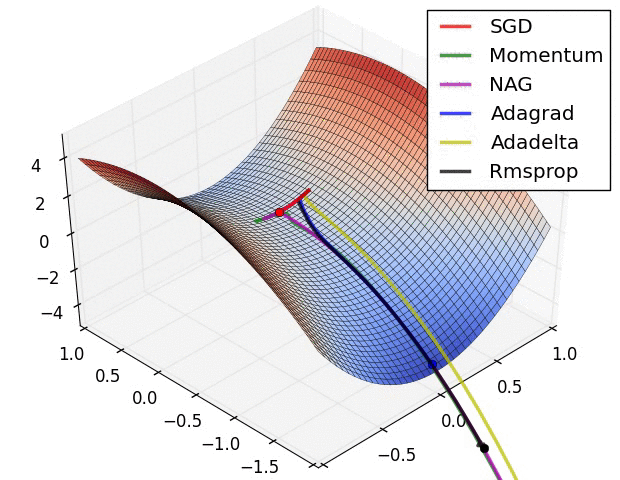
Image credit : https://cs231n.github.io/neural-networks-3/#annealing-the-learning-rate
Why Learning Rate Matters
The learning rate directly affects a model’s ability to learn efficiently and accurately. It’s one of the most crucial hyperparameters in training neural networks, impacting:
- Training Speed: A good learning rate speeds up training by taking appropriately sized steps.
- Model Performance: A well-tuned learning rate helps reach better accuracy by avoiding unstable training or premature convergence.
- Optimization Efficiency: Dynamic approaches like CLR can provide a balanced pace for exploring and fine-tuning, potentially reaching better results, especially in tasks with complex data.

- When training deep learning models, especially in computer vision, selecting the right learning rate can make or break a model’s performance. Traditionally, learning rates start high and gradually decrease throughout training.
However, a more dynamic approach known as Cyclical Learning Rate (CLR) Schedules has proven effective for faster convergence, better accuracy, and improved generalization. Here’s a closer look at CLR schedules, their benefits, and why they’re transforming computer vision model training.
Understanding the Basics: What is a Cyclical Learning Rate Schedule?
A learning rate (LR) controls how much a model adjusts its weights during each training step. In a cyclical learning rate schedule, the LR doesn’t just decrease monotonically but instead oscillates between a minimum and maximum boundary throughout training. This oscillation helps the model explore and learn dynamically across training phases.
Some popular CLR patterns include:
- Triangular: The LR linearly increases to a peak and then decreases, repeating this cycle. It’s simple and effective for early-stage learning.
- Triangular2: Similar to the triangular pattern, but halves the peak LR at the start of each new cycle, creating finer tuning over time.
- Exponential: The LR oscillates within a decreasing range, which can stabilize learning in later stages of training.
The Need for Cyclical Learning Rates in Computer Vision
Computer vision tasks, like image classification, object detection, and segmentation, require deep neural networks trained on large datasets. However, such tasks present challenges:
- Complex Loss Landscapes: Deep neural networks often have highly complex loss landscapes, with many local minima and saddle points.
- Risk of Overfitting: Prolonged training on large data can lead to overfitting, where the model becomes too specific to training data and loses generalization ability.
- Tuning Challenges: Selecting a single, ideal LR that balances speed and accuracy for the entire training process is difficult.
Using cyclical learning rates helps tackle these challenges by enabling:
- Exploration and Avoidance of Local Minima: Oscillating LRs encourage the model to escape local minima or saddle points, where learning might otherwise stagnate.
- Faster and Stable Convergence: Regular boosts to the LR allow the model to explore the loss surface more aggressively, leading to faster learning while also preventing instability.
- Robustness and Improved Generalization: By varying the LR over cycles, CLRs can help reduce overfitting and improve the model’s performance on unseen data.
Implementing CLR in Computer Vision Models
Most popular deep learning frameworks, such as PyTorch, Keras, and TensorFlow, support cyclical learning rates. Let’s go over implementations for these frameworks:
Keras Implementation:
from tensorflow.keras.callbacks import CyclicLR
clr = CyclicLR(base_lr=0.001, max_lr=0.006, step_size=2000, mode="triangular")
model.fit(X_train, y_train, epochs=30, callbacks=[clr])PyTorch Implementation:
from torch.optim import Adam
from torch.optim.lr_scheduler import CyclicLR
optimizer = Adam(model.parameters(), lr=0.001)
scheduler = CyclicLR(optimizer, base_lr=0.001, max_lr=0.01, step_size_up=2000, mode="triangular")
for epoch in range(epochs):
train(model, optimizer) # train step
scheduler.step() # update learning rateHow to Choose CLR Parameters
Selecting appropriate CLR parameters is crucial to get the most benefit:
- Base and Max Learning Rates: Start with a lower base rate (e.g., 1e-5) and choose an upper rate that allows substantial learning (e.g., 1e-2 or 1e-3, depending on the model and dataset). A simple trick to estimate the max LR is to run a quick test using an exponentially increasing LR until the loss stops decreasing.
- Cycle Length (Step Size): For computer vision tasks, a typical cycle length can range from 500 to 10,000 iterations, depending on the dataset size and model. Shorter cycles can be helpful for larger datasets, while longer cycles work well for smaller datasets.
Benefits of Cyclical Learning Rates for Computer Vision
- Escape Local Minima with Regular Boosts: Deep networks in computer vision can encounter local minima and saddle points due to the complex nature of image data. By cycling the learning rate, models are periodically “nudged” out of potential traps, potentially landing in a better global minimum.
- Faster Training Time: Because the learning rate periodically increases, the model explores the loss surface more aggressively, leading to faster convergence. For large computer vision datasets, this can mean reduced training time and fewer resources required.
- Mitigated Overfitting and Improved Generalization: In computer vision tasks, models are prone to overfitting, especially when trained for many epochs. By oscillating the LR, cyclical schedules keep the model from getting “comfortable” with one pattern of learning, which helps it generalize better to unseen data.
- Enhanced Adaptability: Since CLR schedules allow a range of LRs, they reduce the need to tune a single, ideal LR. This flexibility is helpful when using varied datasets with complex image features, where the ideal LR may change over time.


Real-World Examples of CLR in Action
- Image Classification: In complex image datasets like CIFAR-100 or ImageNet, CLR schedules can enhance training stability and performance by enabling models to avoid stagnation in the loss surface. Studies have shown that CNNs, such as ResNet and DenseNet, trained with CLR schedules often reach higher accuracy faster.
- Object Detection: In object detection, models often struggle with high variance due to complex scenes and multiple objects. Using CLR schedules helps these models adapt better to variability in the data, potentially increasing mAP (mean Average Precision) scores.
- Segmentation: In medical image segmentation, where data is limited and specialized, CLR can help balance exploration and fine-tuning, leading to better boundary detection and feature recognition.
Best Practices When Using CLR in Computer Vision
- Start with Small LR Range: For sensitive models, a narrow range of learning rates, such as between 1e-5 and 1e-3, can prevent unstable oscillations.
- Watch the Loss Curve: If the loss curve oscillates too dramatically, the LR range may be too wide. Consider reducing the upper boundary.
- Combine with Regularization: CLR schedules work well alongside other regularization methods, such as dropout and batch normalization, helping models generalize more effectively.
Conclusion: Unlocking New Potential with Cyclical Learning Rates
Cyclical Learning Rates bring a fresh approach to model training by allowing learning rates to oscillate dynamically. For computer vision tasks that involve complex data and require deep learning architectures, this method can offer a robust balance between rapid learning and stable convergence. By adopting CLR schedules, data scientists and engineers can unlock improved performance, reduced training time, and greater adaptability in their computer vision models. For those looking to maximize the potential of computer vision networks, CLR schedules can be a powerful tool in the training toolkit.