Large Language Models (LLMs) have demonstrated great performance in Natural Language Processing (NLP) applications. However, they have high computational costs when fine-tuning them, which can lead to incorrect information being generated, i.e., hallucinations. Two viable strategies have been established to solve these problems: parameter-efficient methods such as Low-Rank Adaptation (LoRA) to minimize computing demands and fact-checking to minimize hallucinations.
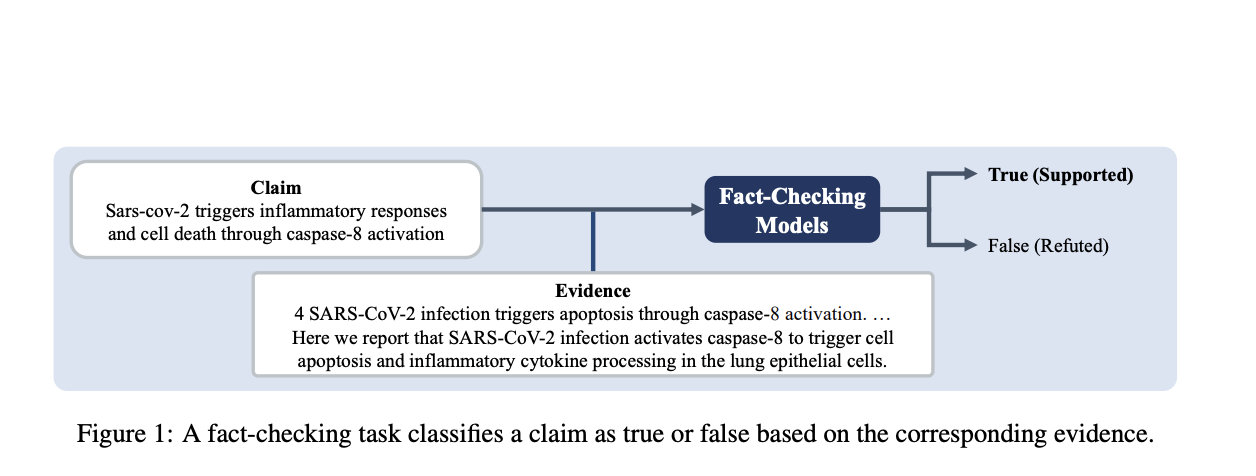
Verifying the accuracy and dependability of LLM results requires careful fact-checking. Fact-checking can detect and lessen the hallucinations that LLMs may cause by comparing text generated by the model with reliable sources. This procedure is especially crucial in fields like journalism, law, and healthcare, where accuracy is vital. Models that undergo fact-checking are better able to retain their credibility, which makes them more appropriate for use in crucial applications.
However, the enormous computational resources needed to fine-tune LLMs have historically prevented them from being widely used. This has been addressed by LoRA, a parameter-efficient fine-tuning strategy, which only modifies a subset of the model’s parameters instead of the network as a whole. This deliberate modification lowers the processing burden and enables more effective LLM task adaptability without compromising performance.
Although LoRA has demonstrated effectiveness in mitigating computational load, researchers have studied the feasibility of concurrently amalgamating numerous LoRAs to manage disparate tasks or viewpoints. Most research has concentrated on the parallel integration of these LoRAs, as in the LoraHub technique, which computes the weighted sum of many LoRAs in parallel. Despite its effectiveness, this strategy might only partially capitalize on the distinct advantages of each specific LoRA, which could result in less-than-ideal performance.
In order to overcome this constraint, current work has redirected its attention from merely integrating disparate LoRAs in parallel to creating links between them. The objective is to facilitate insight sharing and mutual learning between distinct LoRAs, each honed on particular reasoning tasks. The implementation of an integrated method has the potential to augment the LLM’s capacity for complicated tasks such as fact-checking by fostering a more holistic reasoning aptitude.
Within this framework, the research presents three reasoning datasets created especially for tasks involving fact-checking. Every dataset is utilized to fine-tune individual LoRAs, enabling them to make different kinds of arguments. Then, using a unique strategy known as LoraMap, these specialized LoRAs are strategically placed and linked. In order to facilitate communication and improve their capacity for collective thinking, LoraMap aims to map and connect the many LoRAs.
The team has summarized their primary contributions as follows.
- Three specialized reasoning datasets have been created especially for fact-checking assignments. Each dataset is utilized to fine-tune independent Low-Rank Adaptations (LoRAs), enabling them to infer information from different perspectives.
- The team has looked at ways to link logical LoRAs and has presented a new strategy known as LoraMap. Taking its cues from the way the brain processes information in neuroscience, LoraMap discovers relationships between LoRAs instead of just joining them linearly.
- Upon evaluating LoraMap on the COVID-Fact dataset, it displayed superior performance compared to current approaches like LoraHub. It performed better than LoraConcat, obtaining superior outcomes with a notably smaller number of parameters, demonstrating its effectiveness and efficiency in optimizing LLMs for intricate reasoning assignments.
In conclusion, improving computational efficiency with methods like LoRA and reducing hallucinations through fact-checking are critical advancements for LLMs. LoraMap provides a more sophisticated and efficient method of optimizing LLMs for intricate reasoning tasks by going beyond parallel integration and emphasizing the relationships between various LoRAs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.