

I am an Experimental AI Epistemologist. Born in Sweden, now a US Citizen living in Silicon Valley. I have an MS in CS with a minor in EE from Linköping University. Language is my thing. I am a polyglot (English, Swedish, Finnish, German, and some French) and have used 30+ computer languages professionally.
I have 23 years of experience of LLM research. Not a joke. Fewer than 10 people can make this claim. I am likely also the world’s foremost expert on the difference between 20th Century and 21st Century AI; they are close to polar opposites, but most people (even in the AI business) have not noticed this, leading to cognitive dissonances caused by trying to reconcile these gross differences. My outreach focuses on clarifying this. As a hint, Paperclip Maximizers are old AI and now totally irrelevant.
I invent theories for how LLMs should work, based on much more bioplausible models than current LLM designs, and then I test these theories by implementing my own kind of LLMs in Java, C, and Clojure.
This research started on Jan 1, 2001, (on top of a career in industrial strength 20th Century AI, centered around NLP and Lisp) and has been entirely self funded using income and stock options from Google and a few short term employments and consulting. A handful of co-researchers working for equity have helped out over the years but the current design is all mine. I own all the IP. For now, I use trade secret protection.
I evangelize my Epistemology-level ideas in my AI Meetups, in my Substack, on Facebook, and in a dozen videos (more videos in the pipeline). I am an accomplished public speaker. I ran the Silicon Valley AI Meetup for 100+ meetups over 5 years (2 per month). Most of these featured an hour of my “AI Improv” where I lead the audience to discover new truths about AI.
Research Overview
See a list of links to published results at bottom of page.
My LLMs use discrete Pseudo-neurons and pseudo-synapses of a trivial but epistemologically adequate design. The differences to current LLMs are striking; there are many, but these should demonstrate the magnitude of the difference:
Popular LLMs vs. Organic Learning
Semantics First vs. Syntax First
Analog concept space vs. Connectome of discrete neurons
Euclidean distance vs. Jaccard Distance
SGD, Backpropagation vs Neural Darwinism
Differentiable vs. Not a requirement
GPUs vs. Not a requirement (won’t even help)
Token based input vs. Character based input
Embeddings vs. Connectome Algorithms
Parameters vs. Synapse count
Size limited by GPU RAM vs. Size limited by main memory
Learns in cloudmonths vs. Learns any language syntax in 5 mins
The algorithm is described in Chapters 8 and 9 (links at bottom)
Note that the algorithm of my 4 year old demo only handles syntax based (but machine learned, and could have been in any language) classification, not dialog. Beyond this, I have also adapted GPT style token prediction to my system and I’m implementing that now. No publishable results yet. Syntax is enough for most 20th century NLP tasks, such as spam/hate/ad filtering and message classification, and my system would still have a market, if it wasn’t for the runaway success of ChatGPT, which changed the funding landscape.
On the other hand, syntax learning is super cheap and super fast, and can adequately handle many NLP/NLU tasks much cheaper than current LLMs, and the ability to test a new model after a few minutes of learning is invaluable to LLM development turnaround time.
On a Mac x86 laptop, OL learns enough English syntax to score 100% correct on my non-adversarial, out-of-corpus, and simple but fair classification test (see github link for code and test data).
It learns in under 5 minutes and the UM1, the inference engine, can serve almost 1 M characters per second for embedding on any reasonable machine. Half that speed on a RPi 4. If you call the UM1 REST service with just text, the results are the pseudo-neuron unique identifiers that were reached during the Understanding of the text, as a vector.
Chapter 8 has a short video of my laptop learning English in real time and repeatedly running my test. The energy requirements to running GPUs in the cloud has been recognized as a major problem. My systems could be homeschooled on any laptop.
I use “Connectome Algorithms” to discover abstractions, synonyms, and correlates. These are not quite working yet, but indications are that they will still be much cheaper than using GPUs. Although not a fair comparison, it is notable that I estimate my speed and energy advantage of my Syntax Learning over current LLMs to be about a millionth of the time and energy to train a GPT. The Connectome Algorithms use a bit more compute. But still no GPUs, and no cloud required.
My Computing Resources
Below is a picture of my research setup. Each of the two 55” monitors ($320 FireTVs from Amazon) can be connected to four different computers. Two Macs, one Linux box with 2 GPUs (for testing competing LLMS) and one Linux box named “oliver” (named after Oliver Selfridge, the first AI Epistemologist), with 1.5TB or RAM for my own algorithms. The amount of language that “oliver” could learn is likely much much larger than what modern 80GB GPUs can hold.
One Mac is outside my AirGap for web access, all others are inside.
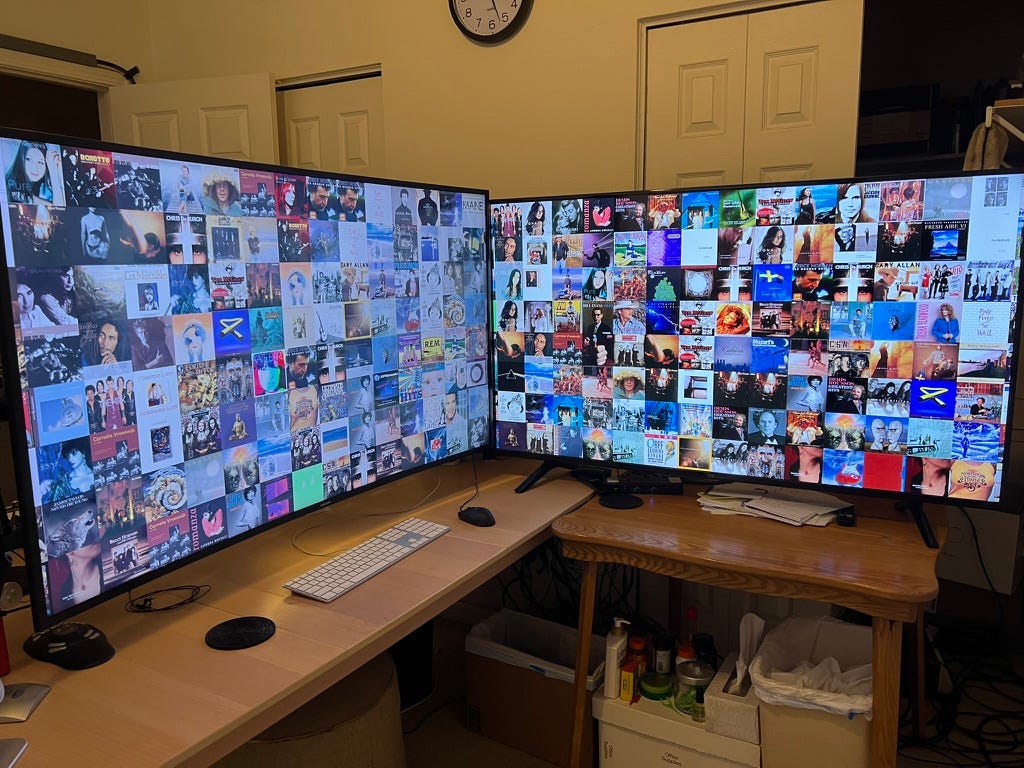
I also maintain three servers in the cloud.
Funding
I recently lost my main patron (since 5+ years) and am looking for new ways to finance this research. I am open to providing interviews, corporate workshops about my theories, and co-development deals with corporations, and any employment that allows me to keep all current and future IP to my implementations.
I may consider VC funding but have not pitched anyone since I pitched A16z in 2017, and I feel that I’m very close to making language generation work, and therefore should defer pitching until I can demonstrate it … because the company valuation would then be 1000-fold higher.
Links
I haven’t been in academia since college (I was teaching college level AI as an undergrad) and cannot even publish to arXiv without two published authors vouching for my competence. So I have no academic publications.
3 minute silent video on AI Alignment (summarizing the Substack post):
Research home page: https://experimental-epistemology.ai
Most important: https://experimental-epistemology.ai/the-red-pill-of-machine-learning/
My LLM: https://experimental-epistemology.ai/organic-learning/
UM1 inference in cloud: https://experimental-epistemology.ai/um1/
I publish most of my material early (for feedback) to Facebook: https://www.facebook.com/pandemonica/https:/
AI Politics Blog on SubStack: https://zerothprinciples.substack.com
Older videos on vimeo: https://vimeo.com/showcase/5329344
Zeroth Principles Meetup: https://www.meetup.com/silicon-valley-artificial-Intelligence/
Blog from 2007: https://www.artificial-intuition.com/
Corporate page: https://syntience.com/
My ideas about “anti-social” spam/hate/ad-free social media:
Bubble City PDF V.2. https://syntience.com/BubbleCity2.pdf
(V.3 will be published in three parts to my SubStack shortly):
Github to test UM1 server: https://github.com/syntience-inc/um1
Some interviews:
https://www.youtube.com/watch?v=Wj2TQor5QPY
https://www.youtube.com/watch?v=Y82sMnvPYKU
https://www.youtube.com/watch?v=2ehIRRyNNTo
My robot: https://www.youtube.com/watch?v=REzrYWOzhWc
Bonus: My profile picture is from a group dinner with friends in June 2024. Do you recognize the gentleman sitting next to me, a friend since 20 years? If you do not, google his T-shirt which says “Potrzebie!” He likes his privacy and I rarely share this.
