
Toyota Research Institute Researchers have unveiled Multi-View Geometric Diffusion (MVGD), a groundbreaking diffusion-based architecture that directly synthesizes high-fidelity novel RGB and depth maps from sparse, posed images, bypassing the need for explicit 3D representations like NeRF or 3D Gaussian splats. This innovation promises to redefine the frontier of 3D synthesis by offering a streamlined, robust, and scalable solution for generating realistic 3D content.
The core challenge MVGD addresses is achieving multi-view consistency: ensuring generated novel viewpoints seamlessly integrate in 3D space. Traditional methods rely on building complex 3D models, which often suffer from memory constraints, slow training, and limited generalization. MVGD, however, integrates implicit 3D reasoning directly into a single diffusion model, generating images and depth maps that maintain scale alignment and geometric coherence with input images without intermediate 3D model construction.
MVGD leverages the power of diffusion models, known for their high-fidelity image generation, to encode appearance and depth information simultaneously
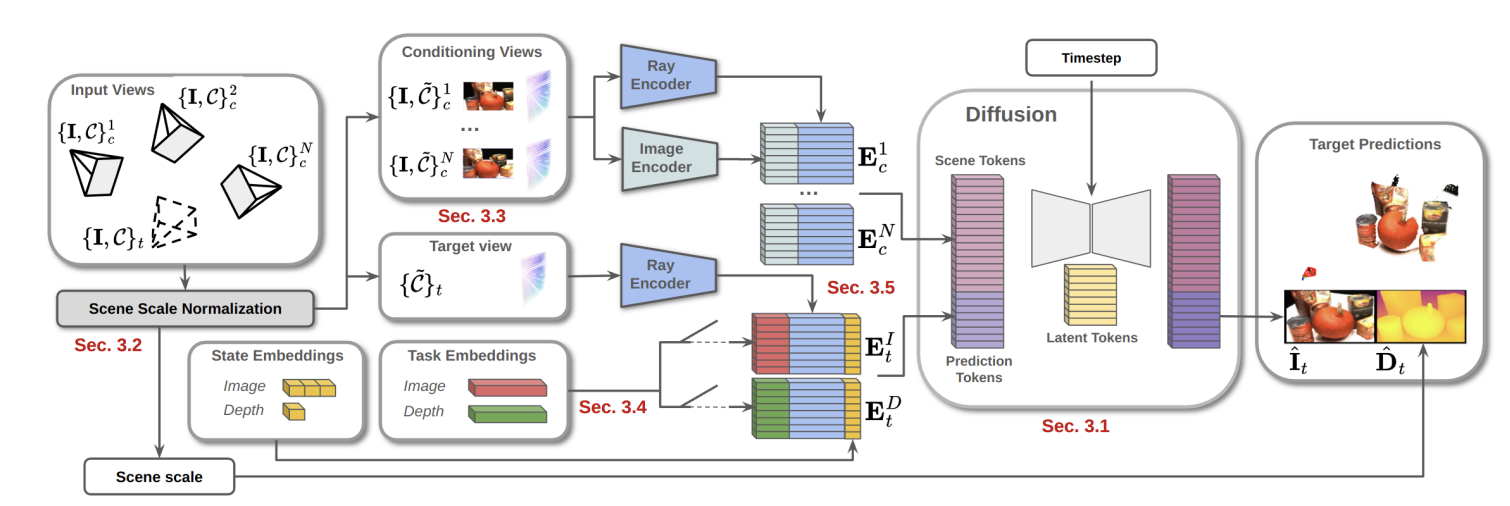
Key innovative components include:
- Pixel-Level Diffusion: Unlike latent diffusion models, MVGD operates at original image resolution using a token-based architecture, preserving fine details.
- Joint Task Embeddings: A multi-task design enables the model to jointly generate RGB images and depth maps, leveraging a unified geometric and visual prior.
- Scene Scale Normalization: MVGD automatically normalizes scene scale based on input camera poses, ensuring geometric coherence across diverse datasets.
Training on an unprecedented scale, with over 60 million multi-view image samples from real-world and synthetic datasets, empowers MVGD with exceptional generalization capabilities. This massive dataset enables:
- Zero-Shot Generalization: MVGD demonstrates robust performance on unseen domains without explicit fine-tuning.
- Robustness to Dynamics: Despite not explicitly modeling motion, MVGD effectively handles scenes with moving objects.
MVGD achieves state-of-the-art performance on benchmarks like RealEstate10K, CO3Dv2, and ScanNet, surpassing or matching existing methods in both novel view synthesis and multi-view depth estimation.
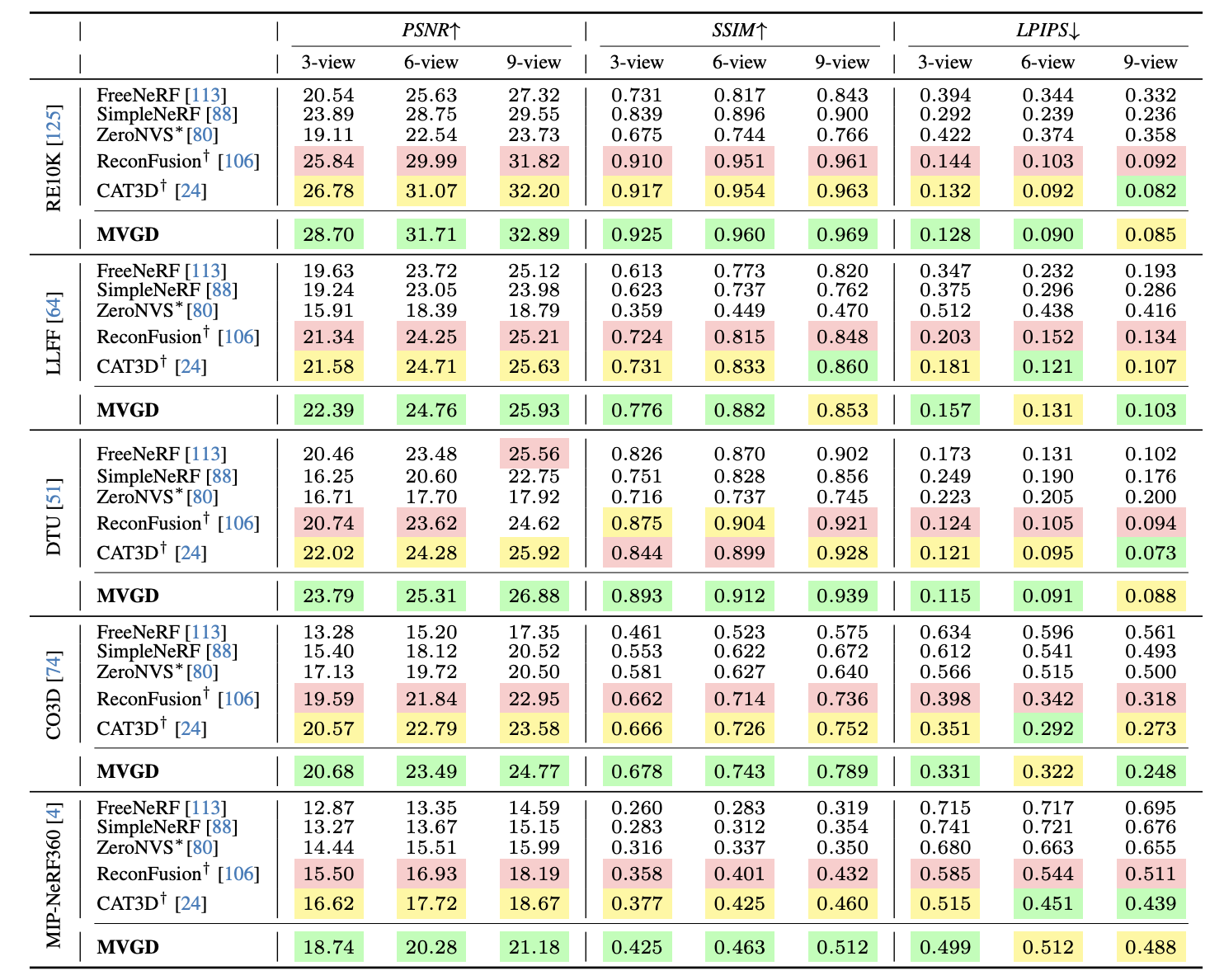
MVGD introduces incremental conditioning and scalable fine-tuning, enhancing its versatility and efficiency.
- Incremental conditioning allows for refining generated novel views by feeding them back into the model.
- Scalable fine-tuning enables incremental model expansion, boosting performance without extensive retraining.
The implications of MVGD are significant:
- Simplified 3D Pipelines: Eliminating explicit 3D representations streamlines novel view synthesis and depth estimation.
- Enhanced Realism: Joint RGB and depth generation provides lifelike, 3D-consistent novel viewpoints.
- Scalability and Adaptability: MVGD handles varying numbers of input views, crucial for large-scale 3D capture.
- Rapid Iteration: Incremental fine-tuning facilitates adaptation to new tasks and complexities.
MVGD represents a significant leap forward in 3D synthesis, merging diffusion elegance with robust geometric cues to deliver photorealistic imagery and scale-aware depth. This breakthrough signals the emergence of “geometry-first” diffusion models, poised to revolutionize immersive content creation, autonomous navigation, and spatial AI.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.
🚨 Recommended Read- LG AI Research Releases NEXUS: An Advanced System Integrating Agent AI System and Data Compliance Standards to Address Legal Concerns in AI Datasets

Jean-marc is a successful AI business executive .He leads and accelerates growth for AI powered solutions and started a computer vision company in 2006. He is a recognized speaker at AI conferences and has an MBA from Stanford.