
OpenAI didn’t release any new models at its Dev Day event but new API features will excite developers who want to use their models to build powerful apps.
OpenAI has had a tough few weeks with its CTO, Mira Murati, and other head researchers joining the ever-growing list of former employees. The company is under increasing pressure from other flagship models, including open-source models which offer developers cheaper and highly capable options.
The new features OpenAI unveiled were the Realtime API (in beta), vision fine-tuning, and efficiency-boosting tools like prompt caching and model distillation.
Realtime API
The Realtime API is the most exciting new feature, albeit in beta. It enables developers to build low-latency, speech-to-speech experiences in their apps without using separate models for speech recognition and text-to-speech conversion.
With this API, developers can now create apps that allow for real-time conversations with AI, such as voice assistants or language learning tools, all through a single API call. It’s not quite the seamless experience that GPT-4o’s Advanced Voice Mode offers, but it’s close.
It’s not cheap though, at approximately $0.06 per minute of audio input and $0.24 per minute of audio output.
The new Realtime API from OpenAI is incredible…
Watch it order 400 strawberries by actually CALLING the store with twillio. All with voice. 🍓🎤 pic.twitter.com/J2BBoL9yFv
— Ty (@FieroTy) October 1, 2024
Vision fine-tuning
Vision fine-tuning within the API allows developers to enhance their models’ ability to understand and interact with images. By fine-tuning GPT-4o using images, developers can create applications that excel in tasks like visual search or object detection.
This feature is already being leveraged by companies like Grab, which improved the accuracy of its mapping service by fine-tuning the model to recognize traffic signs from street-level images.
OpenAI also gave an example of how GPT-4o could generate additional content for a website after being fine-tuned to stylistically match the site’s existing content.
Prompt caching
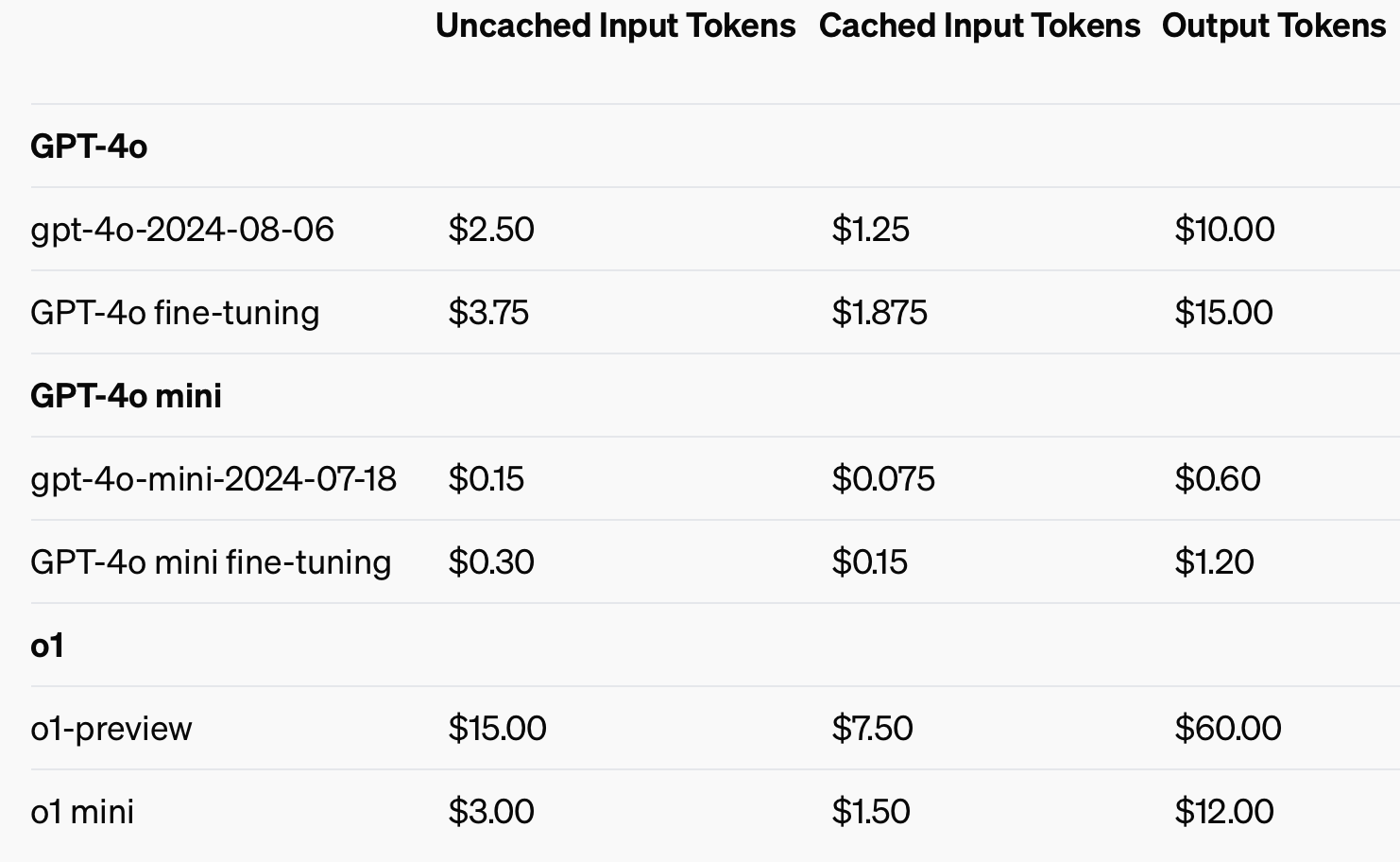
To improve cost efficiency, OpenAI introduced prompt caching, a tool that reduces the cost and latency of frequently used API calls. By reusing recently processed inputs, developers can cut costs by 50% and reduce response times. This feature is especially useful for applications requiring long conversations or repeated context, like chatbots and customer service tools.
Using cached inputs could save up to 50% on input token costs.
Model distillation
Model distillation allows developers to fine-tune smaller, more cost-efficient models, using the outputs of larger, more capable models. This is a game-changer because, previously, distillation required multiple disconnected steps and tools, making it a time-consuming and error-prone process.
Before OpenAI’s integrated Model Distillation feature, developers had to manually orchestrate different parts of the process, like generating data from larger models, preparing fine-tuning datasets, and measuring performance with various tools.
Developers can now automatically store output pairs from larger models like GPT-4o and use those pairs to fine-tune smaller models like GPT-4o-mini. The whole process of dataset creation, fine-tuning, and evaluation can be done in a more structured, automated, and efficient way.
The streamlined developer process, lower latency, and reduced costs will make OpenAI’s GPT-4o model an attractive prospect for developers looking to deploy powerful apps quickly. It will be interesting to see which applications the multi-modal features make possible.