
Building a robot policy that works in the real world isn’t a computer problem anymore — it’s a data problem. Embodied AI teams have three options for fueling their models: teleoperation, simulation, and human video. Each comes with a different cost curve, a different fidelity profile, and a different ceiling on what your robot can ultimately learn. Choosing the wrong primary source can burn six months and a seven-figure budget before you find out. This guide breaks down each data source for embodied AI, where it wins, where it fails, and how to combine them into a production-grade robot training data strategy.
Key Takeaways
- Teleoperation produces the highest-fidelity data but is bottlenecked at 5–50 episodes per operator-hour.
- Simulation generates millions of episodes cheaply but introduces a sim-to-real gap that fails on contact-rich tasks.
- Human video scales effortlessly but lacks robot action labels and carries an embodiment gap.
- Recent research shows roughly 8 simulation samples deliver the value of 1 teleoperated sample for in-domain tasks.
- Most production embodied AI pipelines combine all three sources rather than picking one.
Why is data the bottleneck in embodied AI?
Data is the bottleneck in embodied AI because action-paired sensorimotor data does not exist at internet scale. A language model can ingest a trillion text tokens scraped from the web. A robot policy needs synchronized joint angles, gripper forces, camera frames, and task context — all recorded during physical manipulation. None of that exists for free.
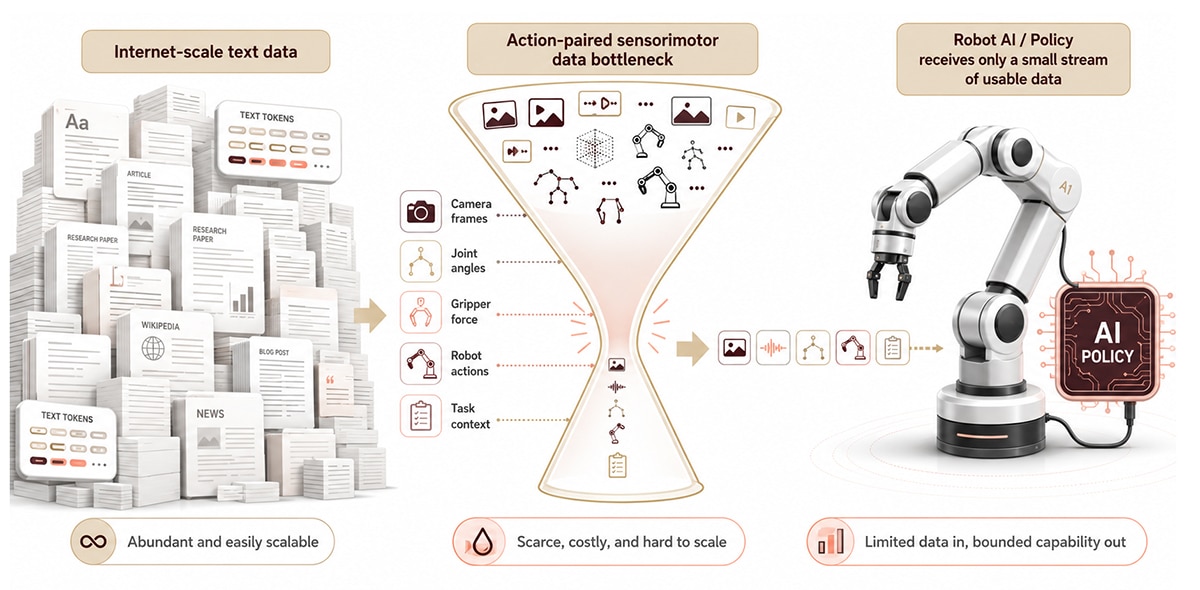
The scale gap is stark. Over 3.9 million industrial robots are operating globally (IFR World Robotics, 2024), yet the largest open robot manipulation dataset contains roughly 1 million episodes (Open X-Embodiment, Padalkar et al., 2023). The hardware is everywhere; the data is not. Every new embodiment — single-arm manipulator, bimanual humanoid, mobile base with an arm — effectively resets data requirements because policies trained on one form factor rarely transfer cleanly to another.
Embodiment gap: The performance loss that occurs when a policy trained on one robot’s physical configuration is deployed on a different robot.
This is why robot learning teams now think in terms of data strategy, not just data collection. The right mix of teleoperation, simulation, and human video defines what your model can do, how fast it ships, and how much you spend getting there.
What is teleoperation data and when does it win?
Teleoperation data is recorded when a human operator controls a robot in real time through a leader arm, VR headset, exoskeleton, or wrist-mounted interface, while the system logs every joint angle, force reading, and camera frame in synchrony.

Teleoperation: Real-time human control of a robot with synchronized sensorimotor data recorded during manipulation.
Teleoperation wins on fidelity. Because the data is generated by a skilled human performing the exact task on the exact robot, the action-state correspondence is perfect and the embodiment gap is zero. Imitation learning, behavior cloning, and policy fine-tuning all benefit from clean teleop demonstrations.
The cost shows up at scale. A skilled teleoperator produces 5–50 episodes per hour depending on task complexity, and quality degrades as operators fatigue. One robot, one operator — that’s the ceiling, and it’s why open platforms like ALOHA, UMI, and exoskeleton-based humanoid rigs (AgiBot, Fourier GR-1) have all focused on cost-down and throughput-up rather than radical scaling.
Shaip’s Physical AI data services operate teleoperation cells alongside multimodal collection workflows so robotics teams don’t have to build operator pipelines from scratch.
What is simulation data and where does it scale?
Simulation data is generated by physics engines — MuJoCo, NVIDIA Isaac Sim, Isaac Lab, PyBullet — that render virtual robots executing tasks across thousands of parallel instances. A single GPU cluster can produce millions of episodes overnight at near-zero marginal cost.
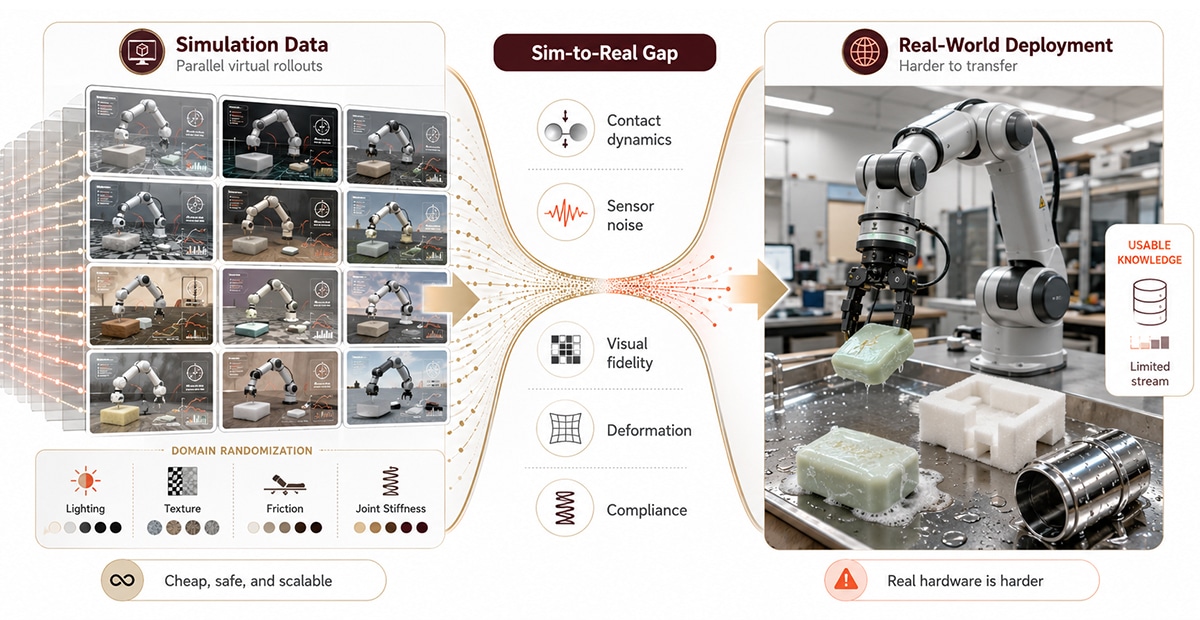
Simulation wins on scale and safety. Edge cases, collision failures, and dangerous configurations can all be explored without breaking hardware. Domain randomization — randomly varying lighting, textures, friction, and joint stiffness during training — produces policies that survive real-world variation rather than overfitting to a single visual configuration.
Sim-to-real gap: The performance drop when a policy trained in simulation is deployed on physical hardware, usually caused by contact dynamics, sensor noise, and visual fidelity differences.
The cost shows up at deployment. Simulators don’t model the friction of a damp soap bar, the give of foam packaging, or the visual variation of specular metal under fluorescent lighting. Contact-rich tasks are where sim-to-real most often breaks. Research published in 2025 quantified the trade-off: roughly 8 simulation samples deliver the equivalent benefit of 1 teleoperated sample for in-domain manipulation tasks (Data Utilization Law for Robotic Manipulation, 2025).
Photorealistic rendering platforms like NVIDIA Cosmos and 3D Gaussian Splatting are narrowing the visual gap, but the dynamics gap — friction, deformation, compliance — remains the harder problem.
What is human video data and what does it unlock?
Human video data is footage of people performing manipulation tasks — folding laundry, stacking dishes, assembling components — captured from egocentric cameras, surveillance angles, or curated demonstration sets.
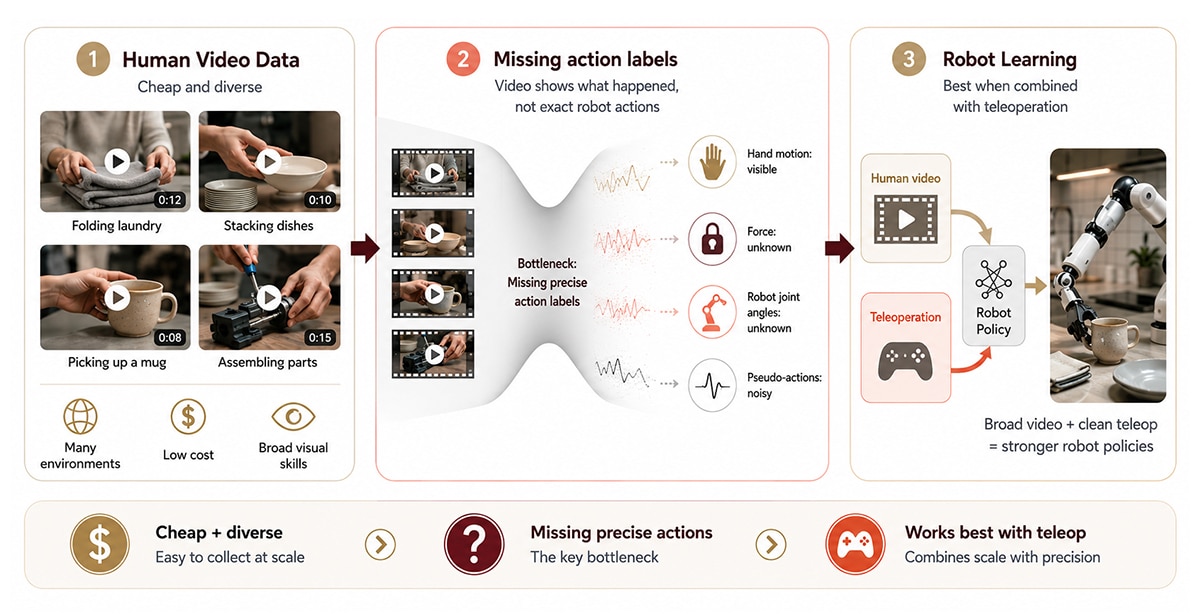
Human video wins on cost and diversity. A single contributor with a smartphone can capture hundreds of demonstrations across kitchens, garages, factories, and offices in a single afternoon. No robot required, no lab required, no operator training required. Large vision-language models pre-trained on human video acquire general scene understanding that transfers usefully to robot policies before fine-tuning.
The limitation is the missing action label. Video shows a hand grasping a mug; it does not record the force applied or the joint angles a robot arm would need to replicate the motion. Inverse dynamics models and hand-to-end-effector retargeting can partially infer those labels, but the resulting pseudo-actions carry noise.
Picture a startup building a kitchen robot. They have $80,000 to spend. Twenty hours of skilled teleoperation might buy them 200 clean episodes on their target arm. Twenty hours of contributor video collection across diverse home kitchens buys them several thousand egocentric clips. The telephone set is sharper. The video set is broader. The robot needs both, in different ratios at different training stages.
Teleoperation vs simulation vs human video: a side-by-side comparison
How do you choose the right data strategy for embodied AI?
Choosing the right robot training data strategy starts with the deployment target, not the data source. A factory pick-and-place robot, a household humanoid, and a surgical assistant have radically different fidelity, safety, and embodiment requirements — and therefore radically different ideal data mixes.
A practical three-step framework:
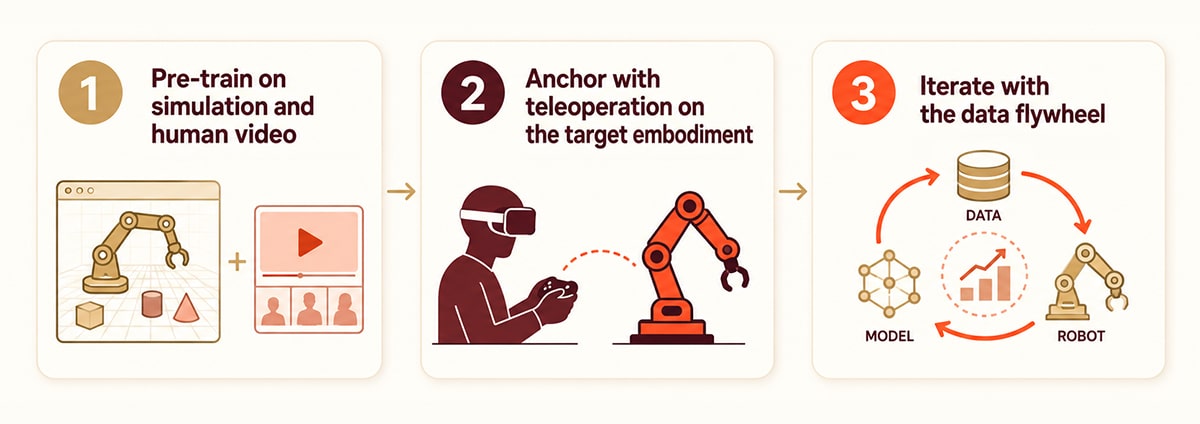
- Pre-train on simulation and human video. Use simulation for broad coverage of scenes, objects, and safety edge cases. Layer in egocentric human video for natural manipulation priors and real-world visual variety. This phase is cheap and broad.
- Anchor with teleoperation on the target embodiment. Collect 500–2,000 high-quality teleop episodes on the exact robot you plan to deploy. This phase is expensive but irreplaceable — it grounds the policy in real dynamics.
- Iterate with the data flywheel. Once deployed, capture autonomous rollouts and failure cases. Feed them back into the next training cycle alongside fresh teleop and human video.
Think of it like training a chef. Simulation is culinary school — broad, cheap, mistake-tolerant. Human video is watching thousands of cooking videos — wide context, no kitchen of your own. Teleoperation is the hands-on internship in the actual kitchen you’ll work in — slow, expensive, irreplaceable. No serious chef skips any of the three.
Shaip’s multimodal data collection and annotation workflows are built to support all three layers — teleop cell operations, simulation labeling, and egocentric video collection through a 500K+ global contributor network — so robotics teams can orchestrate a hybrid strategy without stitching together five vendors.
Conclusion
The teleoperation vs simulation vs human video debate has a clear answer in 2026: it isn’t a choice, it’s a stack. Teleoperation gives you fidelity. Simulation gives you scale. Human video gives you diversity. Production embodied AI pipelines blend all three, weighted to the deployment target, the embodiment, and the budget. The teams that win the next decade of robot learning won’t be the ones that pick the cheapest source — they’ll be the ones that orchestrate the smartest mix.